AI Modeling/軽量化
(On-Device AI)
Running DL Models with the same
performance in small device
Saving 17% of compression rate with the same
accuracy(90%) on image recognition task
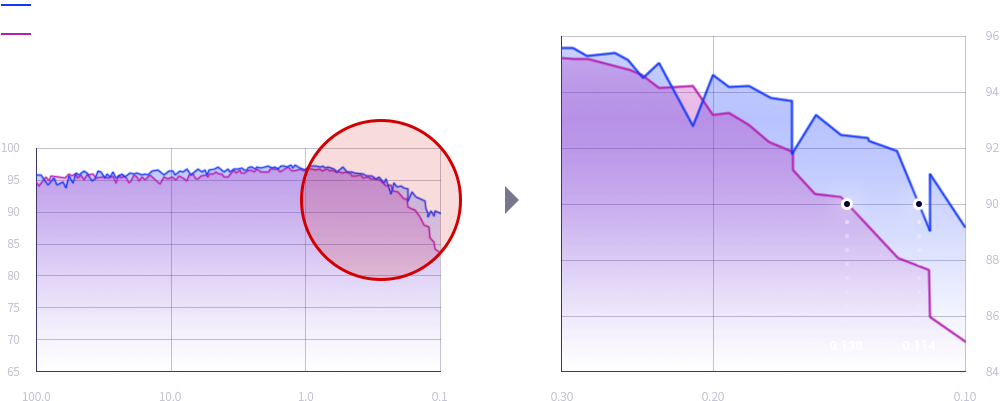
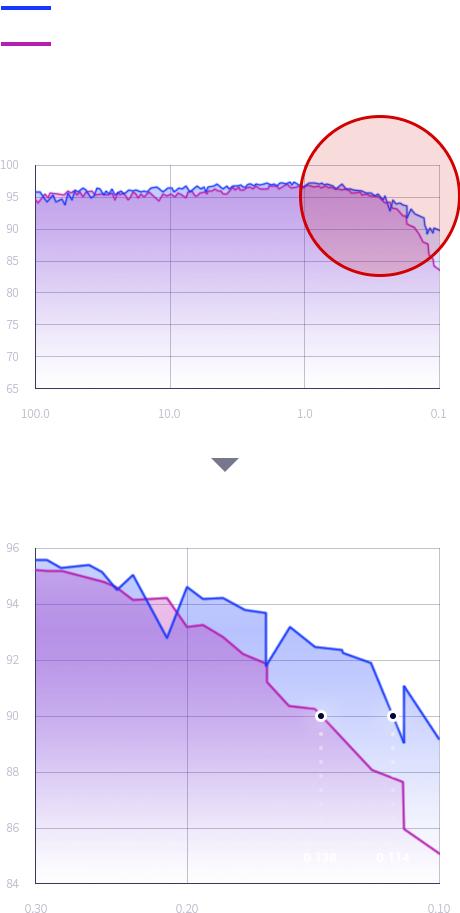
- Saving 17% of compression rate & Same Accuracy(90%)
- Related patents : 3 PCT & 6 KR
競合他社

Nota

-
同一正確度
正確度
既存モデル 97%SAME97%
Raspberry Pi 3+
基盤の顔面認識
モデル基準 -
高効率
演算量
既存モデル 14.4B-85.3%2.3B
Raspberry Pi 3+
基盤の顔面認識
モデル基準 -
速い速度
推論速度
既存モデル 0.38秒-77%0.08秒
Raspberry Pi 3+
基盤の顔面認識
モデル基準 -
省電力
電力消費量
既存モデル 100%-40%60%
顧客での実使用の
データ基準 -
高いコスパ
AIシステム費用
既存モデル 100%-85%15%
顧客での実使用の
データ基準
Compare to Intel OpenVINO &
Nvidia TensorRT
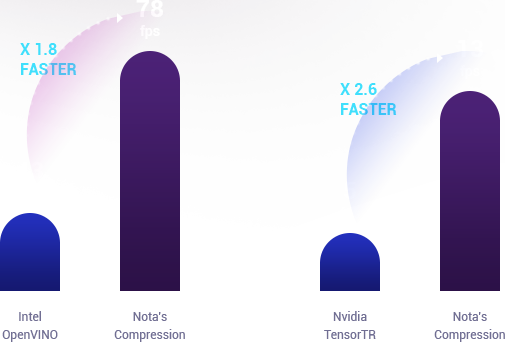
Nvidia TensorRT
- Intel UP2
-
- Intel ATOM x7-E3950
- Intel HD Graphic 505
- 4 GB
- 20 ~ 30 W
* Object Detection on
Intel UP2 board
- CPU
- GPU
- Memory
- Power
- NVIDIA Jetson TX2
-
- ARM Cortex-A5(4core)
- 256 Cuda core(Pascal)
- 8 GB
- 7.5 W
* Object Detection on
Nvidia Jetson TX2 board
Partnership


Nvidia Embedded Partner
Conventional AI model compresion
- Pretrained Model
-
- Compression
Technique - Pruning Quantization
Knowledge Distillation NAS
- Compression
- Compressed Model
Problems of current
network compression
- DL engineers manualy compress the model
- Compression methods are developed in different places and forms
- Hard to know which compression method or combination to use
- Compression metric does not fit to practical metric
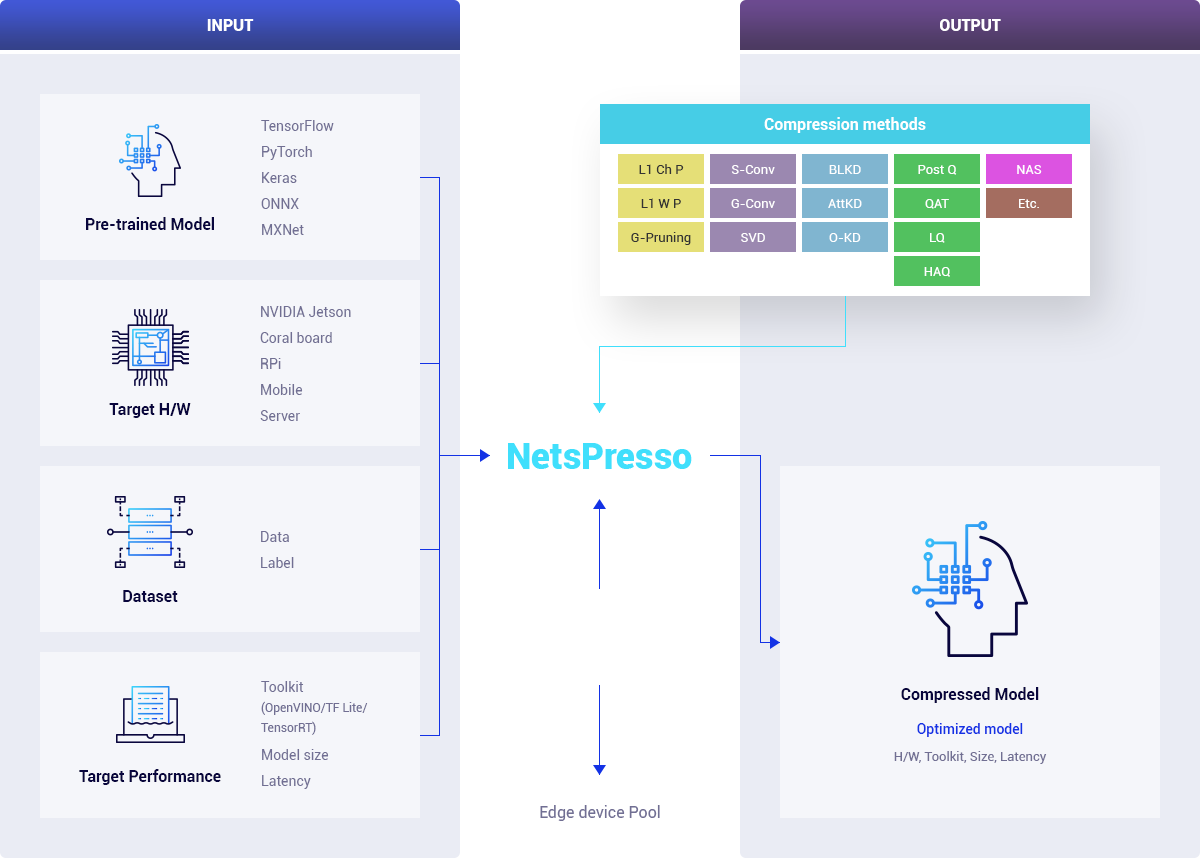
Nota’s NetsPresso(Automatic Model Compression Platform)
-
Problem Soving
- - Automatic compression without manpower
- - Combination of multiple compression methods
- - Fitted metric for practical usage
Nota’s Automatic AI Model Compression Platform : NetsPresso
-
Optimum compression platform for :
- - Target task
- - Target dataset
- - Target device
- - Target accuracy / latency / model size